
 配资公司网
配资公司网
6月30日,摩尔线程与沐曦集成电路同日递交科创板IPO申请,标志着国产GPU企业正式进入资本市场的"决赛圈"。这两家分别估值246.2亿元和210亿元的独角兽企业,凭借创始团队"英伟达+AMD"的豪华背景,在过去三年累计亏损82亿元的情况下仍获得资本市场追捧。与这两家公司同属国产GPU“四小龙”的壁仞科技、燧原科技,也已进入上市辅导阶段。
01
烧钱快,挣钱难
研发投入的天文数字揭示了这个行业的残酷现实:摩尔线程三年投入38.1亿元研发费,是同期营收的6倍;沐曦研发投入占比更是高达282%。
那么GPU到底有多烧钱?
回溯一下近三年,摩尔线程营收分别为4.38 亿、1.24 亿、4609 万;亏损分别为 14.92 亿、16.73 亿、18.4 亿,研发费分别为11.16亿元、13.34亿元、13.59亿元,合计研发投入金额为38亿元。沐曦集成营收分别为42.64万、5302.12万和7.43亿;亏损分别为7.77亿、8.71亿、14.1亿。研发投入分别为6.478亿元、6.99亿元和9亿元,累计研发投入金额为22亿元。虽然近年来两家公司营收有了一些起色,但高额研发投入之下尚未实现盈利。
而此次IPO,两家公司的募资方向也高度一致,均聚焦于新一代芯片的研发工作。
具体来看,摩尔线程在招股书中披露,其计划通过IPO募集80亿元资金,其中约25.1亿元将投入新一代AI训推一体芯片的研发,25亿元用于新一代图形芯片研发,另有19.8亿元专项支持新一代AI Soc芯片的研发。值得一提的是,AI Soc芯片多用于终端设备,与训推一体芯片相比,它具有体积更小、功耗更低的特点,但算力也相对较弱。
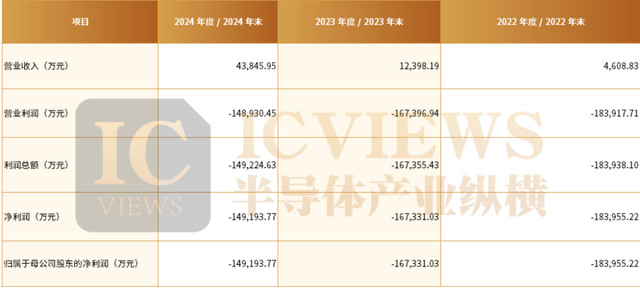
摩尔线程报告期部分财务数据及财务指标
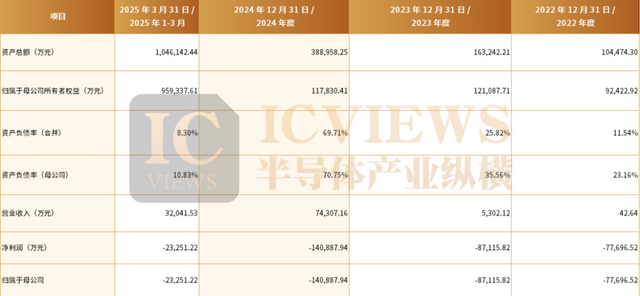
沐曦报告期部分财务数据及财务指标
而沐曦股份则计划募资约39亿元,资金将主要投向高性能通用芯片、AI推理芯片以及前沿场景芯片的开发项目。
这种"用亏损换增长"的模式,在英伟达2009年"显卡门"事件中曾出现过先例——当年亏损8700万美元却仍增加研发投入。但不同的是,中国GPU企业不仅要面对技术追赶的压力,还要应对出口管制带来的供应链风险。
沐曦 2024 年因禁令导致的资产减值损失,并非孤例 —— 从高端光刻机的获取受限,到 EDA 工具的授权收紧,再到晶圆代工产能的优先级倾斜,每一个环节都可能成为卡脖子的节点。摩尔线程招股书中提到的 “核心原材料依赖进口”,沐曦披露的 “替代供应商验证周期长达 18 个月”,都在说明:比起研发投入的数字,供应链的 “抗风险成本” 或许才是更隐蔽的烧钱项。当企业不得不同时维持多条备选供应链,甚至自建封装测试产线时,这场 “烧钱竞赛” 又多了一层无奈的底色。
02
不同的路子
值得关注的是,两家企业的技术路线呈现明显差异。
摩尔线程从一开始就想做“全能选手”。其研发的 MUSA 统一架构,骨子里就带着 “什么都能干” 的基因 —— 一块芯片既要扛得住 AI 计算的密集负载,又得撑得起 3A 游戏的图形渲染,甚至连物理仿真这类专业场景也不想放过。这种思路让它的产品版图铺得很开,既有卖给普通玩家的 MTT S80 游戏显卡,也有数据中心用的 S 系列加速卡,甚至还推出 “长江” SoC 芯片往边缘计算钻。为了快速站稳脚跟,它一边靠创始人的行业积累拉来大笔投资,一边在消费级市场用低价策略抢份额,哪怕利润薄也在所不惜,摆明了要先把生态铺起来。
沐曦集成则显得更“沉得住气”。它的重心从一开始就钉在数据中心,手里的曦云 C 系列芯片,早早就在国家级算力平台上扎了根。和摩尔线程追求 “全功能覆盖” 不同,沐曦更在意技术的 “根正苗红”—— 自研的 MXMACA 指令集从底层就摆脱了对外界的依赖,这种自主架构虽然前期打磨费劲,但胜在可控性强。它的产品节奏也很稳,先把 AI 训练和通用计算的基本盘做扎实,再慢慢推进曦思 N 系列推理芯片,至于图形渲染的曦彩 G 系列,到现在还在研发中。商业上主要盯着 B 端大客户,靠稳定的交付和良率提升一点点扩市场,走的是 “先把专业市场吃透,再图其他” 的路子。
说到底,摩尔线程像在玩一场“全面开花” 的速攻战,想靠全场景覆盖快速建立生态壁垒;而沐曦更像在下一盘慢棋,用自主技术打底,在核心市场里一点点啃下属于自己的地盘。两种路线没有绝对的优劣,只是在国产 GPU 突围的压力下,选择了不同的破局路径而已。
03
比芯片更难啃的“硬骨头”
GPU产业的竞争,早已不是比谁的算力更强那么简单,而是变成了整个生态系统的全面较量。现在国产芯片厂商在晶体管数量、浮点运算能力这些硬件参数上,一步步拉近和国际巨头的距离,但一个更隐蔽却更要命的问题慢慢暴露出来:就算在实验室里性能追平了,可怎么才能让几百万开发者放下用了十几年的CUDA生态,转而来用国产架构呢?这个看起来只是技术迁移的事儿,实际上牵动着整个计算产业的方方面面。
英伟达花了二十年时间把CUDA生态养起来,早就成了一道比芯片本身更难跨越的护城河——注册开发者超500万,合作企业4万家,能兼容的应用软件更是多达上百万款。这意味着,哪怕国产芯片在算力数据上赶上了,开发者要适配新架构,还得花大把功夫改代码,成本可不低。
就像摩尔线程,虽然已经让自家MUSA架构能适配PyTorch、TensorFlow这些主流AI框架,但合作伙伴数量也就英伟达的百分之一,这差距不光是技术兼容的问题,更像是一场争夺开发者认可的持久战。沐曦说自己的MXMACA指令集做到了自主可控,可市场反馈里总绕不开“客户迁移成本太高”——有自动驾驶企业的技术总监就直说了,为了适配新架构,要重构代码,花的钱相当于团队半年的研发预算。这种已经投入的沉没成本形成的惯性,常常让硬件参数的进步变成纸上谈兵,真到了实际场景里,要不要迁移还是个让人头疼的选择。
说到底,生态战争拼的就是怎么留住开发者的时间和精力。英伟达太懂这一点了,它的CUDA工具包不光有编译器、调试器这些基础工具,还靠着英伟达开发者论坛、GTC技术大会这些渠道搭起知识传播的网络,再配上大学里的CUDA课程,从实验室到产业界,人才供应链打得严严实实。
再看国产生态建设,摩尔线程招股书里写着,15%的募资都得花在开发者社区运营和行业解决方案适配上。这种“烧钱”的做法看着无奈,却也说明生态构建有多不容易:得持续投好几年,培养出成千上万懂新架构的开发者,新生态才算真正有了商业上的说服力。
这背后其实是半导体产业的玩法变了。以前拼芯片,就看制程工艺能不能再小几个纳米;现在的战场,早就扩展到“硬件-软件-服务”这三个维度了。英伟达靠着CUDA生态,把技术壁垒从芯片本身延伸到开发工具链,再借着开发者社区形成网络效应,最后在资本市场搞出4000亿美元规模的衍生品交易生态。这种全方位的护城河,哪是靠单一技术突破就能撼动的?
国产芯片厂商想突围,可能得换个思路重新定义竞争:别想着照搬CUDA的工具链,不如针对大模型训练、自动驾驶这些特定场景,做出不一样的开发体验;同时联合高校搞新的知识体系,让开发者迁移生态的时候,不觉得是在增加成本,反而能创造新价值。
现在全球半导体行业都到了“后摩尔定律”时代,GPU生态之争,说到底是比谁的系统工程能力更强。这不光是技术路线的比拼,更是商业模式、人才储备、资本运作的综合较量。国产芯片要啃下这块硬骨头,光靠实验室里的颠覆性创新不够,还得在生态这片土壤里埋下长期主义的种子——毕竟,CUDA那棵参天大树,也是风吹雨打二十年才长成的。
04
资本的耐心阈值
资本市场对技术型企业的包容度,正在经受一场前所未有的考验。就像摩尔线程,246亿元的估值对应着56倍的市销率;沐曦呢,三年加起来营收还不到8亿元,投后估值却能维持在210亿元。这种估值逻辑说白了,就是用“技术可能会突破”替代了“商业价值一定能实现”。国产GPU厂商集体掉进这种估值怪圈,其实也反映出资本市场对硬科技投资的深层焦虑——既要扛住半导体行业研发周期长、花钱如流水的固有特性,又摆脱不了消费互联网时代“快投快赚”的惯性思维。
这种矛盾在Pre-IPO阶段尤其明显。壁仞科技累计融资超50亿元,燧原科技2024年估值也到了160亿元,这些正在准备上市的企业,都面临着“估值倒挂”的风险:一级市场投资者凭着对技术突破的期待把估值抬得高高的,可二级市场更看重能不能持续赚钱,两种逻辑拧不到一起,就形成了危险的剪刀差。2018年AI芯片融资热的时候,不少企业因为没兑现“算力革命”的承诺,最后被资本抛弃,这样的教训还历历在目,也让现在GPU企业的高估值故事显得格外脆弱。
技术要突围,商业要落地,双重压力之下,行业生态快被扯裂了。沐曦虽然去年的营收暴增,但其亏损也同时达到了最高,难以保证足以撑起持续盈利的架子。摩尔线程在图形渲染领域确实有突破,可不得不把15%的募资砸进开发者生态建设,这种“一边搞研发一边补生态课”的烧钱模式,说到底就是在用资本输血填补和国际巨头的技术差距。
资本市场的耐心其实是有刻度的。国产GPU企业都逃不过“研发周期硬约束”:从架构设计到流片量产,至少得24个月,再加上海外竞品更新换代快,留给初创企业的时间窗口可能也就五年。这种时间上的紧箍咒,和资本要求的回报周期撞在一起,矛盾就特别尖锐。
如今,国产 GPU 企业既要证明 “研发投入能转化为技术突破”,更要向市场说明 “商业化路径能跑通”。毕竟,没有哪家资本愿意永远为 “故事” 买单。
想要获取半导体产业的前沿洞见、技术速递、趋势解析配资公司网,关注我们!
驰盈配资提示:文章来自网络,不代表本站观点。
相关文章



热点资讯





推荐资讯
